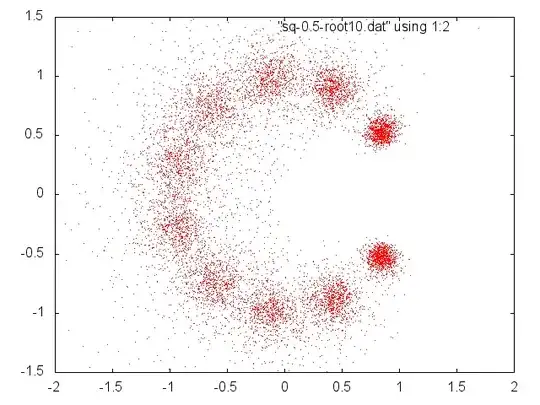
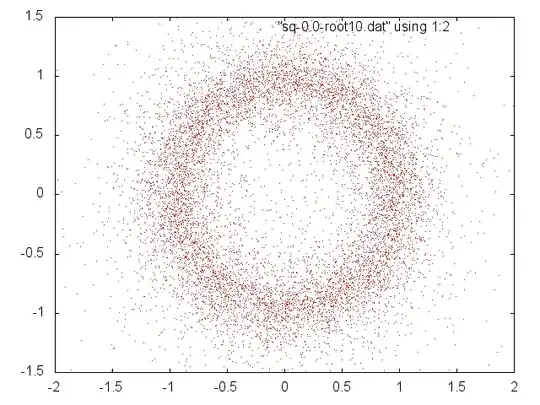
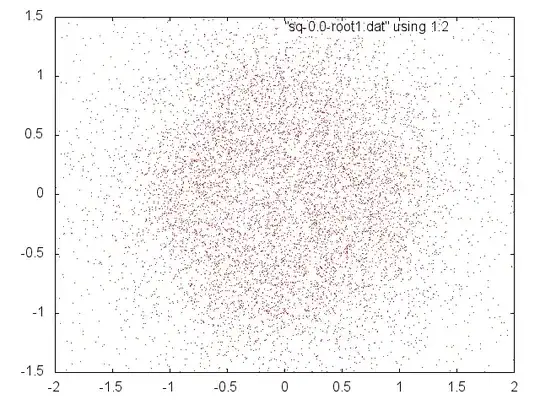
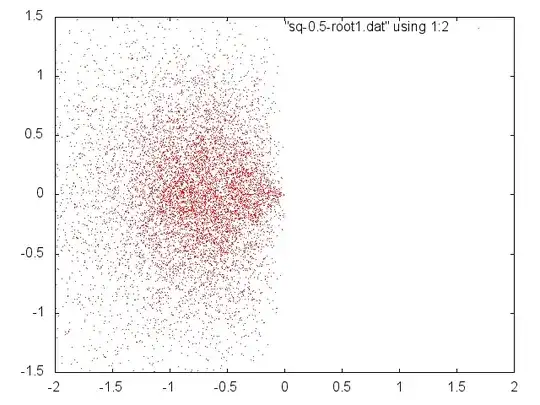
One can explore things visually/experimentally and make good discoveries, Theory is needed to justify them. Here, however, are more experiments and speculation. This is somewhat the same thing looked at in different ways, but I think each adds something.
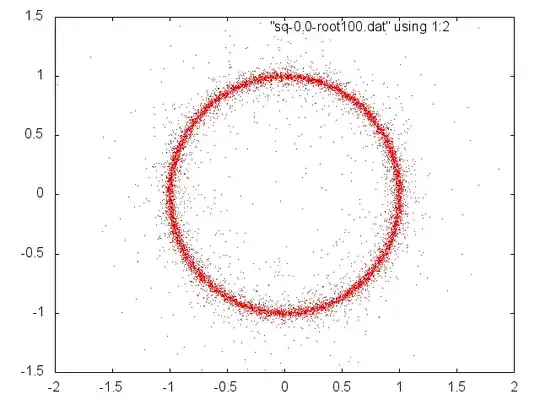
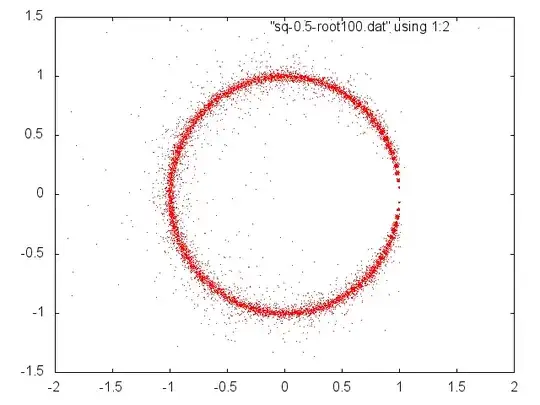
We see that if the (real) coefficients of $p(x)=\sum_0^n a_ix^i$ are drawn randomly from a positive interval then we can normalize to get the same roots with coefficients from $[1-\delta,1+\delta]$ and if $n$ is large enough and $\delta$ small enough relative to each other (whatever that means) the roots will be near the unit circle and almost equally distributed.
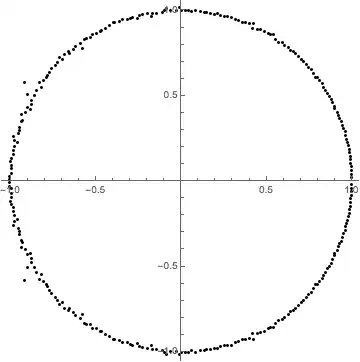
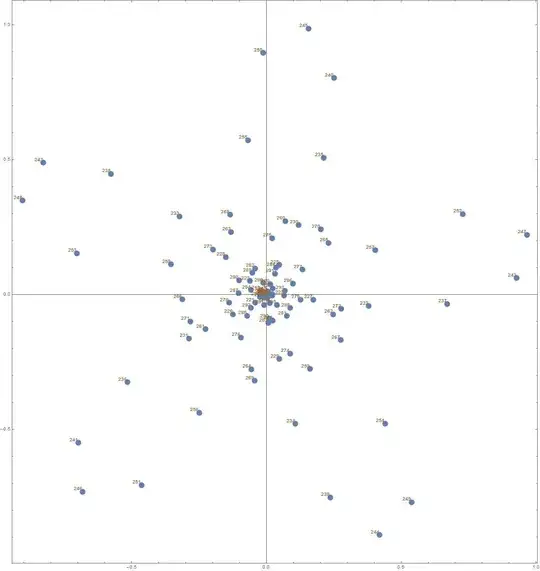
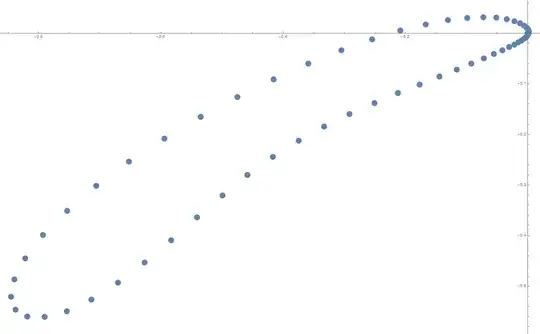
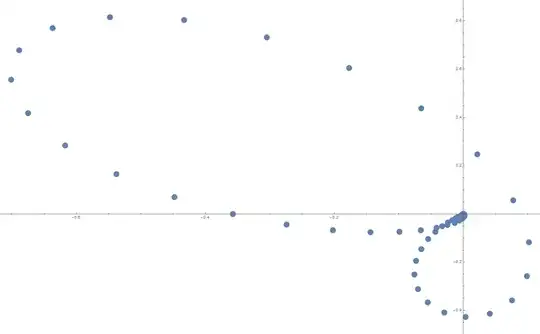
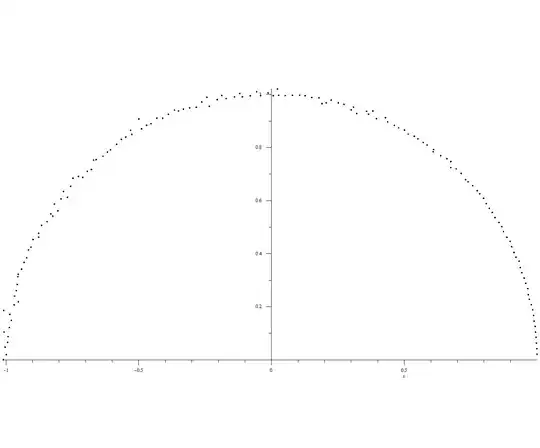
Optional example for illustration and checking: The polynomial $\sum_0^{299}z^n$ has roots $z_m=r_me^{i\theta_m}$ for $r_m=1$ and $\theta_m=\frac{2\pi m}{300}$ $1 \le m \le 299.$ I generated a single random polynomial $f(x)=1+\sum_1^{298} a_n x^x+x^{299}$ with the $a_i$ random and uniformly selected from $[0.8,1.2].$ The $299$ roots (actually, half of them) are shown below. Much can be seen but specifically: The roots, in order of increasing argument, are $r_me^{i \theta_m}$ where in all cases $0.978 \lt r_m \lt 1.036$ and $300|\theta_m-{2\pi m}| \lt 0.78.$ Here are the most extreme deviations in argument (in the upper half):
$[123, -.7783]$, $[73, .7107]$, $[61, -.7036]$, $[100, -.5640]$,
$[56, .5493]$, $[67, -.5482]$, $[102, -.5382]$, $[72, .5213]$,
$[117, .5156]$, $[97, .5099]$, $[43, .4866]$, $[86, .4827]$,
$[87, -.4749]$
Before going on:
- better to say the unit circle except the neighborhood of $1$. Though we could fix that by multiplying through by $x-1$ and discussing polynomials $x^{n+1}+\sum_1^{n}a_ix^i+a_0$ with $a_0$ as before but the $a_i$ in $[-2\delta,2\delta]$ (but denser near $0$.) Then the roots really are almost equally distributed.
- maybe it is better to look at complex coefficients with magnitude in $[1-\delta,1+\delta]$ or $[0,1]$ or $\{{0,1\}}$
- or real coefficients of that form or from one of the sets $\{{-1,1\}},\{{0,1\}},\{{-1,0,1\}}.$
Actually these all relate to each other. Of course small perturbations of coefficients should move roots only a bit. But does that explain how little these moved?
If we are allowed to cook the coefficients to really move a root it seems best to move $-1$ by picking $n$ even and make the coefficients alternately $1-\delta$ and $1+\delta.$
Then $-1$ is no longer a root, $p(-1)=(n+2)\delta.$ But $p'(-1) =\frac{n+2}{2} -\frac{n^2+n}{2}\delta$ is so large that we shouldn't have to go far. In fact calculation shows that the root is roughly $-(1+2\delta).$ More precisely, exactly $-(1+2\delta+2\delta^2\cdots)=-(1+\frac{1+\delta}{1-\delta})$ and the other roots seem unchanged. Of course (in hindsight) we should just factor to see that $$p(x)=((1-\delta)x+(1+\delta))\frac{x^n-1}{x^2-1}.$$
So a root can move more than $2 \delta.$ Is that tight? Seems reasonable, but I'm not going to check. We saw only a fraction of that above. For random coefficients in our model $p(-1)=\sum(a_i-1)(-1)^i$, the sum of $n+1$ values uniformly drawn from $[-\delta,\delta]$ so not that large in relation to $p'(-1)$ . So an actual root is likely not far away at all. As far as it goes, that reasoning is valid for any of the other roots of $\sum x^i$. The root $-1$ is special, but only because we are using real positive coefficients. Arbitrary coefficient near the unit circle should resolve that.
If the cyclotomic roots don't move "much" then they can't end up "too close" together. But perhaps it is also good to just consider if roots (want to be) separated from each other. We could try to add a new root very near an old one or move two roots until they touch or are near. I'll leave it to you to check that, if the other roots are fixed, we get coefficients almost as large as $2.$ Can one do better moving all the roots?
What is the effect of each coefficient? If we change just one interior coefficient $a_k$ to something extremely huge, then there will be seen to be about $n-k$ "big" roots near equally spaced on the circle of radius $a_k^{1/(n-k)}$ and about $k$ "small" roots near the circle of radius $a_k^{-1/k}.$ We can see why. Also, for $k$ not too near either extreme, and $a_k$ merely kind of huge, we would still have all those roots quite close to the unit circle. It is far from obvious how that carries over allowing all the coefficients moving a moderate amount (randomly). Perhaps it could be said that, as long as things like $(\frac{a_{n-k}}{a_n})^{1/k}$ and $(\frac{a_k}{a_0})^{-1/k}$ are all near $1$, there should be many pullings and pushings, none very large, that usually cancel out. That is very vague and unsupported but it works for me as a motivation. With the right deliberate choices we could shove a particular root or small set of roots. That actually seems like the case above for $x=-1.$
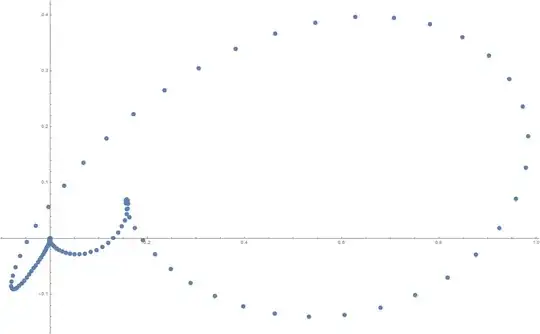
Here is an idea in perhaps more detail than it deserves. If we trace $q(x)=\frac{x^{n+1}-1}{x-1}$ as $x$ moves around the unit circle, we get a path not too hard to describe that touches the origin at the roots and then goes somewhat far away until coming back for the next one. When we perturb the coefficients and look at the position $p(x)$ on the new path, it will differ from the position on the old path by $\sum (a_i-1)x^i$ where these coefficients are random and distributed in $[-\delta,\delta]$ so the $x$ that were (near) roots of $q(x)$ will (usually) be near roots of $p(x)$ and those with $|q(x)|$ not that close to $0$ will? have the same true. It is possible to cook things to get a big deviation in one or a few places but unlikely to happen by random.